
How I Reduced My Query’s Run Time From 30 Min. To 30 Sec. In 1 Hour
The query optimization steps a senior data engineer took to reduce the process time of a query processing 1 billion+ rows.

Despite the terrifying prospect of increasingly sophisticated cyberattacks, one of the quickest ways to break data infrastructure isn’t at all malicious. All you have to do is introduce your ingestion process to something new, typically in a table’s schema.
A new type. A new field. Or, a field disappearing altogether.
The following query optimization case doesn’t begin with frantic Slack messages signaling a crippled pipeline. It isn’t a response to a carelessly added field upstream. It simply starts with a request fellow data engineers get weekly: “Can you add this new field?”
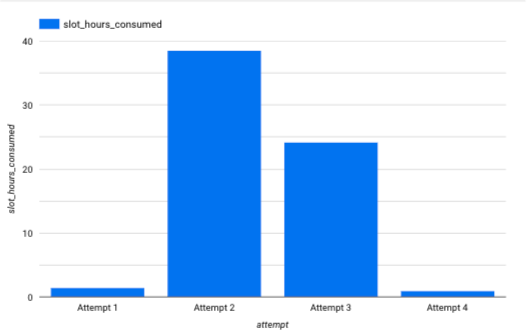
Since this use case was inspired by work, I can’t provide details about the specific data and request. I can tell you, however, that this was a string field that served as a supplemental id. Prior to adding this field, the view I had previously created would execute in less than 15 seconds since it was processing a very small (less than 10,000 rows) amount of data daily.
This quickly increased to 30 minutes.
Below, is a representation of the jump in (approximate) slot hours consumed.
Build Your Pipeline To A Data Engineering Career
You’ve reached the limit of the public preview. The full version of this post includes the implementation details: The code, the edge cases, and the "why" behind the architecture.
When you join PipelineToDE, you get:
- The DA → DE Pathway Course: A structured roadmap to bridge the gap between analysis and engineering.
- Weekly Senior Deep Dives: Fresh, tactical insights on Python, Cloud (GCP/AWS), and modern orchestration delivered every week.
- Production-Ready Blueprints: Access to 80+ protected stories and code repos from my time in the trenches as a Senior DE
- The DE Job Board (Coming Soon): Exclusive access to a curated board of high-agency Data Engineering roles.

