
Beyond Timestamps: Using BigQuery's APPENDS() for Forensic Table Validation
Leverage BigQuery SQL table metadata to deduplicate, partition and delete data — all using only one word.

There are some queries I write so often that I genuinely believe that if I fell asleep on my keyboard, when I would wake up, they’d be entered and running in my SQL environment. Certain functions, especially datetime and timestamp conversions, fall into this category. As do a few simple quality assurance queries.
In journalism school I learned a saying: "If your mother says she loves you, get a second source." The data engineering equivalent of this advice is "If your pipeline's logs say it succeeded, verify your row counts."
One such query that gets row counts by filtering on a given upload date is a go-to to determine how many rows loads to a table in a day.
That looks like this:
SELECT DATE(dt_updated) AS dt_updated, COUNT(1) AS rowCount
FROM `project.dataset.table`
GROUP BY 1 ORDER BY 1 DESCExecuting the above query looks like this:
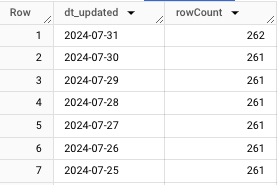
The reason this works so well and so precisely is because we’re able to filter rows by a provided date. This dt_updated column isn’t part of the data I ingest in this case. It’s calculated by the script at runtime, looking something like this:
import pandas as pd
dt_updated = pd.Timestamp.utcnow()But if I hadn’t included that, there would be no reliable, dynamic date field available for filtering. If your data pipelines function predictably this is ok, but not ideal.
If your pipeline suddenly produces duplicate data, this is a big issue.
Just because you don’t have a timestamp field to use for filtering doesn’t mean you’re off the hook in this scenario. A dynamic date field serves several purposes, among them:
- Providing a way to “sanity check” the anticipated volume of ingested data
- Supplying a reference point for partitioning or deleting data
- Enabling SQL developers to write upstream checks in larger orchestration entities like Airflow DAGs
So if we don’t have this field—whether due to legacy tech debt or an upstream vendor’s oversight—we better figure out how to get it. This isn't just about convenience; it's about maintaining data integrity when the schema fails you. Enter one of my favorite BigQuery SQL keywords for forensic table analysis.
APPENDS().
Build Your Pipeline To A Data Engineering Career
You’ve reached the limit of the public preview. The full version of this post includes the implementation details: The code, the edge cases, and the "why" behind the architecture.
When you join PipelineToDE, you get:
- The DA → DE Pathway Course: A structured roadmap to bridge the gap between analysis and engineering.
- Weekly Senior Deep Dives: Fresh, tactical insights on Python, Cloud (GCP/AWS), and modern orchestration delivered every week.
- Production-Ready Blueprints: Access to 80+ protected stories and code repos from my time in the trenches as a Senior DE
- The DE Job Board (Coming Soon): Exclusive access to a curated board of high-agency Data Engineering roles.
